 NUMERIQUE ET
SCIENCES INFORMATIQUES
NUMERIQUE ET
SCIENCES INFORMATIQUES
Niveau : 1ère générale, enseignement de spécialité NSI
D
É
C
O
N
N
E
C
T
É
Chapitre 6 : Machine learning - KNN
1 -Introduction :
Le Machine Learning est un
ensemble de techniques permettant de créer, à partir de données, des
modèles prédictifs qui apprennent par eux-mêmes. L'ordinateur va
s'entrainer sur un jeu de données dont il connait les résultats et sera
ensuite capable de résoudre un problème par lui-même.
Ces machines utilisent bien entendu des algorithmes qui permettent par exemple de vous suggérer des amis sur les réseaux sociaux.
2 - Algorithme des K plus proche voisins
L'algorithme des k plus proches voisins (k-Nearest Neighbors, ou k-NN) est un algorithme d'apprentissage supervisé utilisé pour la classification et la régression. Il repose sur l'idée que des points similaires sont souvent proches les uns des autres dans l'espace des caractéristiques.
Principe
- Définir les données d'entraînement : une collection de points avec leurs coordonnées et leurs classes ou valeurs associées.
- Déterminer un point inconnu pour lequel on veut prédire la classe ou la valeur.
- Calculer la distance entre ce point et tous les points du jeu de données (souvent avec la distance euclidienne).
- Trouver les k plus proches voisins du point inconnu.
- Classification : La classe majoritaire parmi ces k voisins est attribuée au point inconnu.
- Régression : La valeur moyenne des k voisins est attribuée au point inconnu
L'une des distances les plus fréquentes est la distance euclidienne :
Déterminer si l'animal inconnu est un ours ou un phoque ?

Rendez-vous sur le site : http://fred.boissac.free.fr/AnimsJS/Dariush_KVoisins/index.html
Placer des ours, des phoques et un animal inconnu.
Exécuter l'algorithme avec différentes valeurs de k.
D'autres distances peuvent être utilisées, comme la distance de Manhattan ou la distance de Minkowski.
Calcul de la distance :
Les animaux seront stockées dans une liste contenant un dictionnaire.
Ecrire une fonction distance qui prend en paramètre animal, un animal de la liste, un dictionnaire inconnu avec les coordonnées de l'animal inconnu
La fonction retourne la distance séparant l'animal de l'inconnu.
Ne pas omettre d'écrire la documentation de la fonction.
Vérifier que :
>>>distance(animaux[2],animal_inconnu) 7.211102550927978 >>>distance(animaux[10],animal_inconnu) 1.4142135623730951
Trier
trier la liste des animaux en fonction de la distance qui les sépare de l'animal inconnu.
Implanter le programme de tri par insertion par un copier coller du chapitre des algorithmes de tri.
Ajouter la variable inconnu en 2ème paramètre de la fonction
Modifier la condition de la boucle tant que de la manière suivante :
tant que j est supérieur ou égal à 0 et que la distance entre l'animal en_cours et l'animal inconnu est inférieur à la distance entre l'animal se trouvant à l'index j et l'animal inconnu faire
Compléter le programme ci-dessus en rajoutant la fonction qui prendra en paramètre t la liste des animaux et inconnu, l'animal inconnu.
Vérifier que la liste est triée en appelant la procédure permettant d'afficher les distances.
Prédire l'espèce
Pour prédire l'espèce, on va compter le nombre d'animaux de chaque espèce dans la liste triée des k premiers annimaux et on retournera l'espèce la plus nombreuse. Pour éviter l'égalité, k devra être impair, vous utiliserez l'instruction assert vérifier la valeur de k.
Compléter le programme et vérifier son fonctionnement avec des valeurs de k=1,3 et 5.
>>>print(knn(animaux,1))
phoque
>>>print(knn(animaux,3))
Ours
>>>print(knn(animaux,4))
AssertionError: k doit être impair !
copier-coller le programme précédent dans Edupython et ajouter les lignes suivantes :
Expliquer comment est tracé le cercle en fonction du nombre k de voisins ?
Autre exemple
Nous allons utiliser le jeu de données d'Anderson, du nom d'Edgar
Anderson qui en 1936 a collecté des données de 3 espèces d'iris :"iris
setosa", "iris virginica" et "iris versicolor". Il a mesuré (en cm) :
- la largeur des sépales
- la longueur des sépales
- la largeur des pétales
- la longueur des pétales
 |
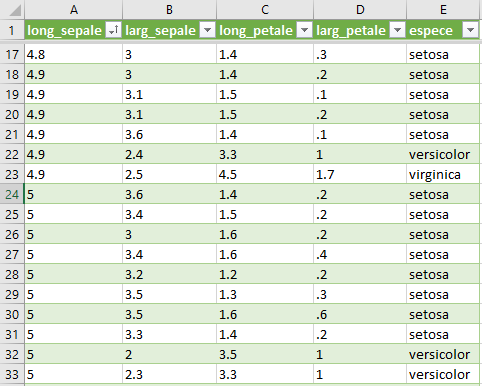 |
Toutes ces données ont été stockées dans un fichier csv qui pourra être lu par une machine.
- la longueur des pétales
- la largeur des pétales
- l'espèce de l'iris
Pour cette partie, il faut commencer par récupérer le fichier iris.csv
Déplacer le fichier dans vos documents, puis créer un nouveau fichier avec edupython et enregistrez-le au même endroit.
Dans un premier temps, nous allons afficher un graphique qui en
abscisse représente la longueur des pétales, en ordonnée la largeur des
pétales et une couleur par espèce (vert pour setosa, rouge pour
viriginica et bleu pour versicolor) pour cela nous utiliserons la
bibliothèque matplotlib.
Pour faire le graphique, il faut d’abord charger le fichier csv pour récupérer les données. Nous allons utiliser la bibliothèque pandas (import pandas).
# Affichage des données du fichier iris.csv
import matplotlib.pyplot as plt
import pandas
donnees = pandas. read_csv ('iris.csv', header =0) # lecture du fichier iris.csv
setosa = donnees[donnees['espece'] == 'setosa'] # setosa contiendra la liste des meures de toutes les espèces d'iris 'setosa'
plt . scatter ( setosa ['long_sepale'], setosa ['larg_sepale'],color='g', label ='setosa') # abscisse : long_petale, ordonnée : larg_petale , color green
plt.xlabel ('longeur sepale') # affichage des label
plt.ylabel ('largeur sepale')
plt.title ('Iris') # titre
plt.legend (); # légende des label
plt.show() # affiche le graphique
Exercice 1 :
Modifier le programme afin d'afficher le graphique des largeurs et longueurs des pétales toutes les espèces permettant d'obtenir le graphique suivant :
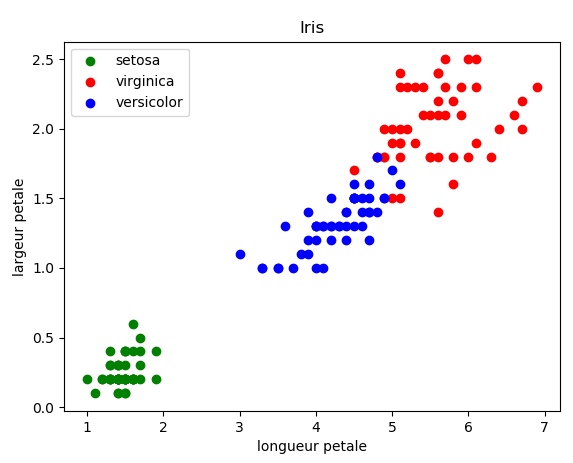
Collez votre code python dans la fenêtre ci-dessous puis cliquez sur enregistrer:
La répartition des points permet de voir que l'espèce setosa est vraiment différente et éloignée des autres espèces, donc facilement différenciable. Par-contre, les iris virginica et versicolor ont des longueurs et largeurs de pétales similaires, des points se mélangent.
Imaginez qu'au cours d'une promenade vous tombiez nez à nez avec un iris. Vous n'êtes pas un spécialiste des iris mais vous souhaiteriez connaître l'espèce. Vous mesurez les dimensions des pétales suivantes : longueur 2cm et largeur 0.5 cm.Faire apparaître ce nouveau point, avec une couleur noire (color='k'), dans le graphique afin de voir à quelle espèce il appartient.
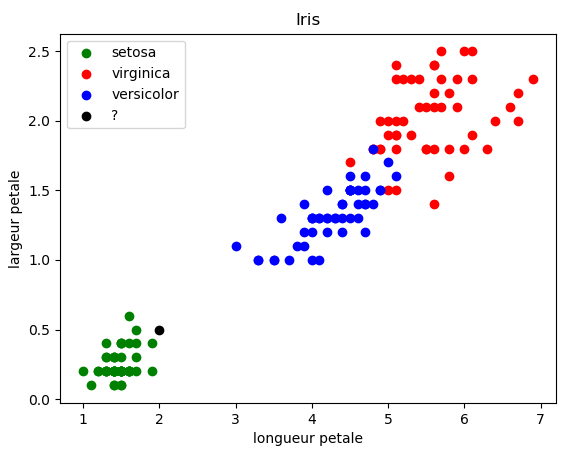
Sans aucun doute, l'iris trouvé fait partie de l'espèce setosa. Mais
qu'en est-il de l'iris ayant les mesures suivantes : longueur = 2,5 et
largeur=0.75
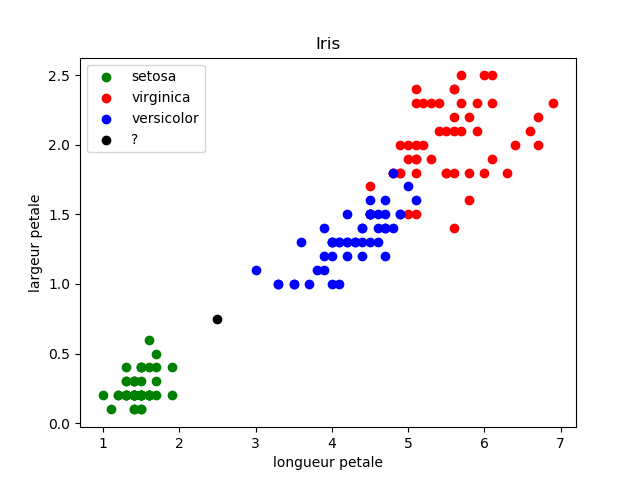
Dans ce genre de cas, il peut être intéressant d'utiliser l'algorithme des "k plus proches voisins"
Prenons k = 3
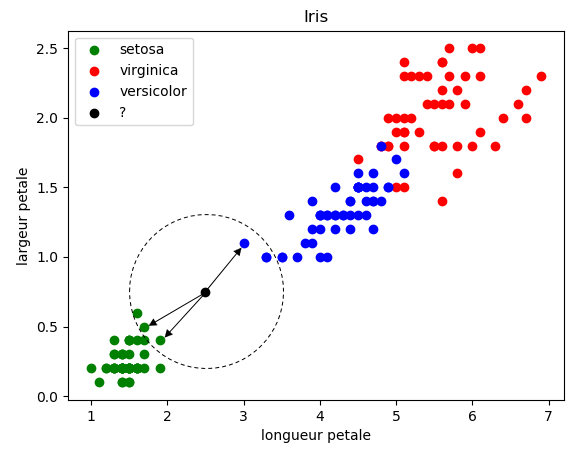
Les 3 plus proches voisins sont signalés ci-dessus avec des flèches : nous avons deux "iris setosa" (point vert) et un "iris virginica" (point bleu). D'après l'algorithme des "k plus proches voisins", notre "iris mystère" appartient à l'espèce "setosa".
La bibliothèque Python Scikit Learn propose un grand nombre d'algorithmes liés au machine learning (c'est sans aucun doute la bibliothèque la plus utilisée en machine learning). Parmi tous ces algorithmes, Scikit Learn propose l'algorithme des k plus proches voisins.
Programme du KNN
étudiez et testez le code suivant :
# Recherche des k plus proches voisins
import matplotlib.pyplot as plt
import pandas
from sklearn.neighbors import KNeighborsClassifier
#traitement CSV
donnees = pandas. read_csv ('iris.csv', header =0)
x=donnees.loc[:,"long_petale"]
y=donnees.loc[:,"larg_petale"]
lab=donnees.loc[:,"espece"]
# Valeurs mesurées:
long_petale=2.5
larg_petale=0.75
k=3
setosa = donnees[donnees['espece'] == 'setosa']
virginica = donnees[donnees['espece'] == 'virginica']
versicolor = donnees[donnees['espece'] == 'versicolor']
plt.scatter(setosa ['long_petale'], setosa ['larg_petale'],color='g', label ='setosa')
plt.scatter(virginica ['long_petale'], virginica ['larg_petale'],color='r', label ='virginica')
plt.scatter(versicolor ['long_petale'], versicolor ['larg_petale'],color='b', label ='versicolor')
# algorithme KNN
d=list(zip(x,y))
model = KNeighborsClassifier(n_neighbors=k)
model.fit(d,lab)
prediction= model.predict([[long_petale,larg_petale]])
#Affichage résultats
plt.xlabel('longueur petale')
plt.ylabel('largeur petale')
plt.title('Iris')
plt.legend();
plt.scatter(long_petale,larg_petale,color='k',label=prediction)
txt="Résultat : " + prediction[0]
plt.text(3,0.5, "largeur : " + str(larg_petale) + " cm longueur : " + str(long_petale)+ " cm", fontsize=12)
plt.text(3,0.3, "k : " + str(k), fontsize=12)
plt.text(3,0.1, txt, fontsize=12)
#fin affichage résultats
plt.show()la ligne "d=list(zip(x,y))" permet de passer de 2 listes x et y
x = [1.4, 1.4, 1.3, 1.5, 1.4, 1.7, 1.4, ...]
y = [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.4,....]
à une liste de tuples contenant (x,y) de chaque iris
d = [(1.4, 0.2), (1.4, 0.2), (1.3, 0.2) (1.5, 0.2), (1.4, 0.2), (1.7, 0.2), (1.4, 0.4), ...]
"KNeighborsClassifier" est une méthode issue de la bibliothèque scikit-learn (voir plus haut le "from sklearn.neighbors import KNeighborsClassifier"), cette méthode prend ici en paramètre le nombre de "plus proches voisins" (model = KNeighborsClassifier(n_neighbors=k))
"model.fit(d, lab)" permet d'associer les tuples présents dans la liste "d" avec les labels (0 : setosa, 26 : setosa, 120 : virginica ...). Par exemple le premier tuple de la liste "d", (1.4, 0.2) est associé au premier label de la liste lab (0), et ainsi de suite...


La ligne "prediction= model.predict([[longueur,largeur]])" permet d'effectuer une prédiction pour un couple [longueur, largeur] (dans l'exemple ci-dessus "longueur=2.5" et "largeur=0.75").
La variable "prediction" contient alors le label trouvé par l'algorithme knn. Attention, "predection" est une liste Python qui contient un seul élément (le label), il est donc nécessaire d'écrire "predection[0]" afin d'obtenir le label.
>>> print(prediction)
['setosa']
>>> print(prediction)[0]
'setosa'
Vous devriez normalement obtenir ceci :
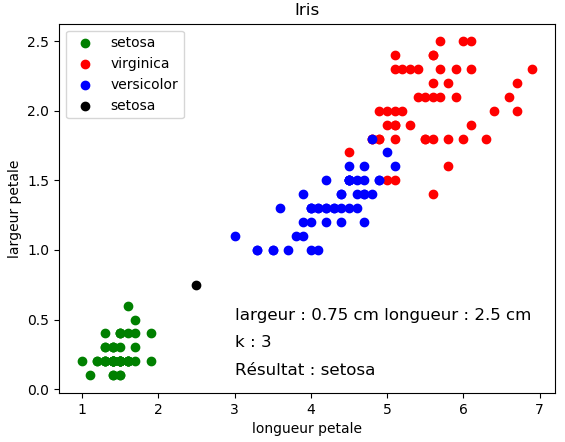
Exercice 2 :
Modifiez le programme afin de tester l'algorithme knn avec un nombre "de plus proches voisins" différent (en gardant un iris ayant une longueur de pétale égale à 2,5 cm et une largeur de pétale égale à 0,75 cm). Que se passe-t-il pour k = 5 ?
Testez l'algorithme knn avec un iris de votre choix en inventant des mesures de pétales.
Notez dans la fenêtre ci-dessous les résultats des prédictions et les tests réalisés pour différentes valeurs de k et d'iris
prise en compte de la largeur des sépales et affichage 3D
import matplotlib.pyplot as plt
import numpy as np
import pandas
from sklearn.neighbors import KNeighborsClassifier
from mpl_toolkits.mplot3d import axes3d
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
#traitement CSV
donnees = pandas. read_csv ('iris.csv', header =0)
x=donnees.loc[:,"long_petale"]
y=donnees.loc[:,"larg_petale"]
z=donnees.loc[:,"larg_sepale"]
lab=donnees.loc[:,"espece"]
# Valeurs mesurées:
long_petale=2.5
larg_petale=0.75
larg_sepale=2
k=3
setosa = donnees[donnees['espece'] == 'setosa']
virginica = donnees[donnees['espece'] == 'virginica']
versicolor = donnees[donnees['espece'] == 'versicolor']
ax.scatter3D(np.array([list(setosa ['long_petale'])],dtype=np.float),np.array([list(setosa ['larg_petale'])],dtype=np.float),np.array([list(setosa ['larg_sepale'])],dtype=np.float),label='setosa')
ax.scatter3D(np.array([list(virginica ['long_petale'])],dtype=np.float), np.array([list(virginica ['larg_petale'])],dtype=np.float),np.array([list(virginica['larg_sepale'])],dtype=np.float),label='virginica')
ax.scatter3D(np.array([list(versicolor ['long_petale'])],dtype=np.float), np.array([list(versicolor ['larg_petale'])],dtype=np.float),np.array([list(versicolor['larg_sepale'])],dtype=np.float),label='versicolor')
# algorithme KNN
d=list(zip(x,y,z))
model = KNeighborsClassifier(n_neighbors=k)
model.fit(d,lab)
prediction= model.predict([[long_petale,larg_petale,larg_sepale]])
print (prediction[0])
#Affichage résultats
ax.scatter3D(np.array([[long_petale]],dtype=np.float), np.array([[larg_petale]],dtype=np.float),np.array([[larg_sepale]],dtype=np.float),label=prediction[0])
ax.legend()
ax.set_xlabel('longueur petale')
ax.set_ylabel('largeur petale')
ax.set_zlabel('largeur sepale')
ax.text2D(-0.05,0.095,"Résultat : "+ prediction[0], fontsize=12)
ax.legend()
#fin affichage résultats
plt.show()
Exercice :
Sans modifier l'affichage 3D (compréhension 4D délicate : avec un
bargraphe), écrire le script permettant de prendre en compte les 4
caractéristiques des iris : la longueur et la largeur des sépales ainsi
que des pétales. Vous pouvez prendre des valeurs déjà existantes dans
le fichier CSV pour vérifier s'il retrouve la bonne espèce.
Collez votre code python dans la fenêtre ci-dessous puis cliquez sur enregistrer:
Exercice 3
Après importé les données du fichier csv, on peut le transformer en dictionnaire par l'instruction suivante : dict_donnees = donnees.to_dict(orient="records")
Avec l'IA de votre choix, adapter le premier programme pour qu'il fonctionne avec la liste des iris ci-dessous.
Collez le programme généré ci-dessous après avoir apporté les éventuelles corrections.
Testez le programme et comparez les résultats.
Expliquez les modifications apportées par L'IA, ainsi que les optimisations apportées.